SQL là một trong những kỹ năng phổ biến nhất trong Khoa học dữ liệu. Trong bài viết này tôi sẽ trình bày cách sử dụng SQL trong Xử lý dữ liệu bằng công cụ BigQuery.
Giới thiệu
SQL (Structured Query Language – Ngôn ngữ truy vấn có cấu trúc) là một ngôn ngữ lập trình được sử dụng để truy vấn và quản lý dữ liệu trong cơ sở dữ liệu quan hệ. Cơ sở dữ liệu quan hệ được hình thành bởi tập hợp các bảng hai chiều (ví dụ: Tập dữ liệu, Bảng tính Excel). Mỗi bảng này sau đó được tạo thành bởi một số cột cố định và một số hàng bất kỳ.
Hãy lấy ví dụ về các nhà sản xuất điện thoại di động. Mỗi nhà sản xuất điện thoại có thể có một cơ sở dữ liệu bao gồm nhiều bảng khác nhau (ví dụ: một bảng cho từng mẫu sản phẩm điện thoại). Trong mỗi bảng này sẽ có các số liệu khác nhau về doanh số bán từng mẫu điện thoại ở các quốc gia khác nhau.
Cùng với Python và R, SQL hiện được coi là một trong những kỹ năng được yêu cầu nhiều nhất trong Khoa học dữ liệu. Một số lý do khiến cho SQL là kỹ năng cần thiết hiện nay:
- Khoảng 2,5 nghìn tỷ byte dữ liệu được tạo ra mỗi ngày. Để lưu trữ một lượng lớn dữ liệu như vậy, cần phải sử dụng các cơ sở dữ liệu (database).
- Các công ty ngày càng coi trọng giá trị của dữ liệu hơn. Ví dụ, dữ liệu có thể được sử dụng để: phân tích và giải quyết các vấn đề kinh doanh, đưa ra dự đoán về xu hướng thị trường và hiểu về nhu cầu của khách hàng.
Một trong những ưu điểm chính của việc sử dụng SQL là khi thực hiện các thao tác với dữ liệu, dữ liệu sẽ được truy cập trực tiếp (không cần sao chép trước). Do đó thời gian thực hiện công việc giảm đáng kể.
Có nhiều cơ sở dữ liệu SQL khác nhau như: SQLite, MySQL, Postgres, Oracle và Microsoft SQL Server.
Trong bài viết này, tôi sẽ giới thiệu cách bắt đầu miễn phí với SQL bằng cách sử dụng Google BigQuery được tích hợp trên Kaggle.
Google giới thiệu về BigQuery như sau:
BigQuery là kho dữ liệu để doanh nghiệp giải quyết các vấn đề bằng cách cho phép truy vấn SQL siêu nhanh, sử dụng sức mạnh xử lý của cơ sở hạ tầng của Google. Chỉ cần di chuyển dữ liệu của bạn vào BigQuery và để chúng tôi xử lý công việc khó khăn còn lại.
Nguồn: https://cloud.google.com/bigquery/docs/introduction
Bắt đầu với BigQuery
Để sử dụng BigQuery, trước hết chúng ta cần tạo một tài khoản Google Cloud Platform miễn phí.
Lựa chọn vào mục BigQuery trên Google Cloud Platform, bạn có thể làm việc trên các bộ dữ liệu (dataset) mẫu sẵn có thuộc nhiều lĩnh vực khác nhau (Hình 1), tải lên file dữ liệu, hoặc kết nối với các cơ sở dữ liệu như MySQL hoặc PostgreSQL.
Nguồn: https://console.cloud.google.com/
Ngoài ra, khi sử dụng Kaggle Kernels (phiên bản trực tuyến của Jupyter Notebooks được tích hợp trong hệ thống Kaggle), có một tùy chọn để bật Google BigQuery. Kaggle cung cấp dịch vụ BigQuery miễn phí lên đến 5 terabyte (5TB) một tháng cho mỗi người dùng (nếu bạn dùng hết giới hạn này, bạn sẽ phải đợi đến tháng tiếp theo).
Trước hết chúng ta cần có một tài khoản Google Cloud Platform và một bản sao của dự án trên Google Service của mình. Bạn có thể tìm thấy ở đây hướng dẫn về cách bắt đầu chỉ trong vài phút.
Sau khi tạo dự án BigQuery trên Google Account Platform, chúng ta sẽ nhận được một Project ID. Trong trường hợp này tôi sử dụng bộ dữ liệu trên Kaggle có tên là “E-commerce Shipping Data” (https://www.kaggle.com/prachi13/customer-analytics). Project ID của tôi trên Google Cloud là “huy-nguyen-kaggle”. Tôi tải về bộ dữ liệu này từ Kaggle và tải lên Google Cloud dưới dạng file .csv, đặt tên bộ dữ liệu là “ecommerce”. Bây giờ tôi có thể kết nối Kaggle Kernel của mình với BigQuery bằng cách chạy một vài đoạn code như sau trên Kaggle Notebook.
- Chỉ ra Project ID có chứa bộ dữ liệu:
# Identify the project ID containing the desired dataset for analysis in this kernel
PROJECT_ID = 'huy-nguyen-kaggle'
2. Import BigQuery API từ thư viện của google.cloud
# Import the BQ API Client library
from google.cloud import bigquery
client = bigquery.Client(project=PROJECT_ID, location='US')
3. Liên kết tới bộ dữ liệu ecommerce có trong dự án BigQuery
# Construct a reference to the ecommerce dataset that is within the project
dataset_ref = client.dataset('ecommerce', project=PROJECT_ID)
4. Lấy dữ liệu từ bộ dữ liệu trên
# Make an API request to fetch the dataset
dataset = client.get_dataset(dataset_ref)
Xem trước Tập dữ liệu của bạn
Bây giờ bạn có một tập dữ liệu biến có chứa tập dữ liệu BigQuery mà bạn muốn sử dụng trong kernel này. Đối với ví dụ này, điều đó có nghĩa là bây giờ tôi đã có bộ dữ liệu thương mại điện tử ecommerce của mình. Bây giờ tôi có thể xem trước các nội dung của bộ dữ liệu bằng các đoạn code sau:
- Xem danh sách tên các bảng (table) trong bộ dữ liệu
# Make a list of all the tables in the dataset
tables = list(client.list_tables(dataset))
# Print names of all tables in the dataset
for table in tables:
print(table.table_id)
Kết quả (output):
Ecommerce
2. Xem trước 5 dòng đầu tiên của bộ dữ liệu
# Preview the first five lines of the table
client.list_rows(table, max_results=5).to_dataframe()
Kết quả (output):

Viết và chạy truy vấn SQL (hoặc nhiều truy vấn SQL)
Bây giờ chúng ta đã có dữ liệu của mình, ta có thể bắt đầu thực hiện công việc chính: viết và chạy một truy vấn SQL. Có thể bạn muốn viết một truy vấn để lấy một tập con cụ thể của tập dữ liệu. Hoặc có thể bạn có một câu hỏi cụ thể về dữ liệu và bạn muốn trả lời nó thông qua một truy vấn. Tất cả đều có thể thực hiện với kernel. Ở đây, tôi sẽ lấy ví dụ một truy vấn trả lời các câu hỏi cụ thể về tập dữ liệu ecommerce.
Ví dụ chúng ta muốn biết phương thức vận chuyển nào là phổ biến nhất với mỗi mức độ quan trọng của hàng hóa, chúng ta có thể dùng truy vấn sau:
# What is the most common mode of transport with different levels of product importance?
query = """
SELECT
DISTINCT Product_importance AS Product_importance,
Mode_of_Shipment AS Mode_of_Shipment,
COUNT(ID) AS Count
FROM
`huy-nguyen-kaggle.ecommerce.ecommerce`
GROUP BY
Mode_of_Shipment,
Product_importance
ORDER BY
Product_importance,
Count DESC
"""
query_job = client.query(query)
query_job.to_dataframe()
Kết quả (output):
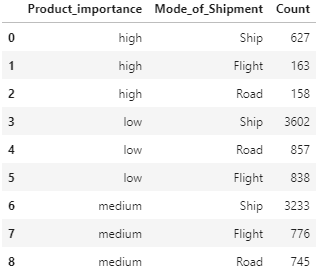
Từ bảng kết quả truy vấn trên, chúng ta có thể thấy phương thức vận chuyển bằng tàu thủy (Ship) là phương thức vận chuyển phổ biến nhất với cả 3 mức độ quan trọng của hàng hóa.
Kết luận
Trên đây là giới thiệu khái quát về cách bắt đầu sử dụng BigQuery SQL để truy vấn dữ liệu. Nếu bạn muốn tìm hiểu thêm về SQL, bạn có thể theo dõi các khóa học miễn phí Kaggle Intro to SQL và SQLBolt. Chúc bạn thành công!