Xác suất thống kê đóng một vai trò quan trọng trong các dự án về khoa học dữ liệu. Mọi nhà khoa học dữ liệu đều phải áp dụng xác suất thống kê để hiểu rõ hơn về bộ dữ liệu và trích xuất các thông tin chi tiết. Do đó, một nhà khoa học dữ liệu nhất thiết phải hiểu rõ về các khái niệm thống kê cơ bản.
Trong bài viết này, tôi sẽ cung cấp cho bạn thông tin chi tiết về các khái niệm thống kê cơ bản thường được sử dụng trong khoa học dữ liệu và một số ví dụ minh họa
1. Chọn mẫu (Sampling)
Chọn mẫu (sampling) là việc lựa chọn một tập hợp con dữ liệu từ toàn bộ dữ liệu tổng thể (population). Ví dụ một công ty muốn hiểu rõ hơn về sở thích của khách hàng. Việc yêu cầu tất cả khách hàng tham gia vào một cuộc khảo sát đôi khi không khả thi do số lượng khách hàng là quá lớn. Khi đó chúng ta cần lựa chọn một nhóm đối tượng mục tiêu từ tập hợp toàn bộ khách hàng của công ty để tiến hành khảo sát, việc lựa chọn này chính là quá trình chọn mẫu (sampling). Trong khuôn khổ bài viết này, tôi sẽ chỉ đề cấp đến các phương pháp chọn mẫu theo xác suất (probability sampling). Chọn mẫu theo xác suất dựa trên giả định là mọi thành viên của quần thể đều có cơ hội được chọn. Đây là phương pháp thường được sử dụng trong nghiên cứu định lượng để tạo ra kết quả nghiên cứu mang tính đại diện cho toàn bộ tổng thể. Có bốn phương pháp chọn mẫu theo xác xuất chính:
Phương pháp chọn mẫu ngẫu nhiên đơn giản (Simple random sampling)
Phương pháp chọn mẫu ngẫu nhiên đơn giản là phương pháp mà trong đó chúng ta chỉ chọn mẫu một cách ngẫu nhiên từ dữ liệu tổng thể.
Ví dụ trong trường hợp khảo sát khách hàng của công ty nói trên, bạn muốn chọn ra ngẫu nhiên 100 khách hàng từ tổng số 1000 khách hàng của công ty. Bạn gán cho mỗi khách hàng trong cơ sở dữ liệu một mã số đại diện (ID) từ 1 đến 1000, sau đó sử dụng trình tạo số ngẫu nhiên để tạo ra 100 số rồi chọn các khách hàng có mã số ID này.
Nhược điểm của phương pháp này là chúng ta có thể vô tình bỏ qua những dữ liệu quan trọng có trong bộ dữ liệu gốc, do đó mẫu chúng ta chọn có thể không đại diện được cho tổng thể.
Phương pháp chọn mẫu có hệ thống (Systematic sampling)
Chọn mẫu hệ thống tương tự như chọn mẫu ngẫu nhiên đơn giản, nhưng còn thường dễ tiến hành hơn một chút. Mọi thành viên của quần thể đều được gắn với một con số, nhưng thay vì chọn các số ngẫu nhiên, các cá thể được chọn theo một quy luật nhất định.
Ví dụ tất cả 1000 khách hàng của công ty được liệt kê theo số thứ tự từ 1 đến 1000. Trong 10 số đầu tiên, bạn chọn ngẫu nhiên một điểm bắt đầu: số 8. Từ số 8 trở đi, cứ cách 10 số bạn chọn một số (8, 18, 28, 38, v.v.), cuối cùng bạn sẽ có được một mẫu gồm 100 khách hàng.
Khi sử dụng phương pháp này, điều quan trọng là bạn phải chắc chắn không có quy luật ẩn nào trong việc sắp xếp các mẫu của tổng thể dẫn đến làm thiên lệch việc lựa chọn. Ví dụ: nếu cơ sở dữ liệu khách hàng được liệt kê theo các nhóm, và trong mỗi nhóm khách hàng lại được sắp xếp theo thứ tự từ mới đến cũ, thì rất có thể với cách chọn mẫu như trên bạn sẽ chọn hầu hết khách hàng cũ mà bỏ qua các khách hàng mới.
Phương pháp chọn mẫu phân tầng (Stratified sampling)
Chọn mẫu phân tầng dựa vào việc phân chia toàn bộ quần thể thành các tập hợp con có các đặc tính khác biệt nhau. Điều đó cho phép bạn rút ra kết luận chính xác hơn bằng cách đảm bảo rằng mọi tập hợp con đều được thể hiện đúng trong mẫu.
Để sử dụng phương pháp chọn mẫu này, bạn chia toàn bộ quần thể thành các tập hợp con (được gọi là “strata – tầng lớp”) dựa trên các đặc điểm nhất định (ví dụ: giới tính, độ tuổi, thu nhập, v.v…).
Dựa trên tỷ lệ của mỗi tập hợp trên toàn bộ quần thể, bạn tính toán cần phải lẫy mẫu bao nhiêu người từ mỗi tập hợp con. Sau đó, bạn sử dụng cách chọn mẫu ngẫu nhiên hoặc có hệ thống để chọn một mẫu từ mỗi tập hợp con này.
Ví dụ, công ty có 600 khách hàng nữ và 400 khách hàng nam. Bạn muốn đảm bảo rằng mẫu cũng phản ánh đúng tỉ lệ giới tính của khách hàng, vì vậy bạn sắp xếp toàn bộ dữ liệu khách hàng thành hai tập hợp con dựa trên giới tính. Sau đó, trên tập hợp khách hàng nữ, bạn chọn ngẫu nhiên 60 mẫu, và chọn ngẫu nhiên 40 mẫu trên tập hợp khách hàng nam. Kết quả là bạn có một mẫu 100 khách hàng với đúng tỉ lệ giới tính của toàn bộ khách hàng của công ty.
Phương pháp chọn mẫu theo cụm (Cluster sampling)
Chọn mẫu theo cụm cũng liên quan đến việc phân chia toàn bộ quần thể thành các tập hợp con (được gọi là “cluster – cụm”), nhưng mỗi tập hợp con phải có các đặc điểm tương tự với toàn bộ quần thể. Thay vì chọn một số cá thể từ tất cả các cụm, bạn sẽ chỉ chọn ngẫu nhiên một số cụm nhất định.
Nếu thực tế cho phép, bạn có thể chọn hết tất cả các cá thể từ mỗi cụm dữ liệu. Nếu các cụm quá lớn, bạn cũng có thể chọn chỉ một sổ cá thể từ mỗi cụm bằng cách sử dụng một trong các kỹ thuật chọn mẫu ở trên.
Phương pháp này hữu ích để xử lý các quần thể lớn và phân tán, nhưng có nhiều rủi ro sai sót hơn trong mẫu, vì có thể có sự khác biệt đáng kể giữa các cụm. Rất khó để đảm bảo rằng các cụm được chọn thực sự đại diện cho toàn bộ quần thể.
Ví dụ công ty nói trên có chi nhánh tại 10 thành phố trên toàn quốc (tất cả đều có số lượng khách hàng và các đặc điểm của khách hàng gần như tương tự). Bạn không có khả năng đi đến mọi văn phòng để tiến hành khảo sát, vì vậy, bạn sử dụng phương pháp lấy mẫu ngẫu nhiên để chọn ra 3 văn phòng – đây là các cụm của bạn – rồi từ đó bạn chọn ra tiếp các cá thể từ mỗi cụm này theo một trong ba cách nêu trên.
2. Thống kê mô tả (descriptive statistics)
Thống kê mô tả cung cấp phân tích cấp cao về các tính năng khác nhau có trong tập dữ liệu. Dưới đây là một số kỹ thuật thống kê mô tả thường được sử dụng:
Biểu đồ Histogram
Biểu đồ Histogram rất hữu ích để hiểu sự phân bố của các thuộc tính trong tập dữ liệu. Việc hiểu sự phân bố của các thuộc tính trong tập dữ liệu rất quan trọng, vì nó sẽ quyết định việc cần lựa chọn thuật toán nào để phân tích dự đoán. Ví dụ, khi chúng ta sử dụng thuật toán hồi quy tuyến tính (linear regression), một trong những giả định (assumption) là các thuộc tính đều có phân phối chuẩn (normal distribution). Dưới đây là một ví dụ về biểu đổ Histogram của một phân phối chuẩn:
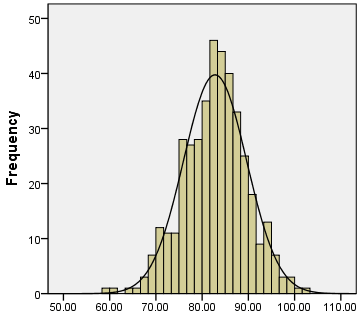
Nguồn: https://libguides.library.kent.edu/SPSS/FrequenciesContinuous
Xu hướng tập trung (central tendency)
Các thước đo khác nhau của xu hướng tập trung là giá trị trung bình (mean), trung vị (median) và yếu vị (mode), những giá trị này được sử dụng để xác định điểm trung tâm trong phân phối. Nhìn chung, giá trị trung bình là một thước đo tốt để xác định điểm trung tâm. Trong trường hợp dữ liệu bị lệch (skew), trung vị có thể là thước đo tốt hơn và trong trường hợp dữ liệu có dạng thứ tự (ordinal), sử dụng trung vị hoặc yếu vị sẽ tốt hơn là giá trị trung bình.

Nguồn: https://guides.douglascollege.ca/stats/centraltendency
Độ nghiêng (skewness) và độ nhọn (kurtosis)
Độ nghiêng (skewness) được sử dụng để xác định xem phân phối là đối xứng (tức là phân phối chuẩn) hay không đối xứng (phân phối lệch). Khi giá trị của độ lệch bằng 0 thì điều đó có nghĩa là phân phối là chuẩn. Giá trị âm có nghĩa là dữ liệu bị lệch âm nghĩa là có một đuôi dài ở bên trái của phân phối và lệch dương có nghĩa là có một đuôi dài ở bên phải của phân phối.
Rất nhiều dữ liệu tài chính sẽ bị lệch về phía bên phải (độ lệch dương), ví dụ tài sản của các cá nhân, giá nhà ở, dữ liệu chi tiêu v.v… Trong tất cả những trường hợp này, giá trị trung bình và trung vị sẽ cao hơn nhiều so với yếu vị, vì mặc dù phần lớn các giá trị sẽ nằm xung quanh yếu vị, sẽ có một số ít các quan sát có giá trị rất cao (ví dụ một vài người giàu nhất sẽ có tài sản vượt xa số đông). Trong khi xây dựng mô hình dự đoán, chúng ta không thể bỏ qua những giá trị đó, nhưng đồng thời cũng không thể đưa ngay các giá trị này vào mô hình, vì nhiều mô hình dự đoán sẽ không sử dụng được với các dữ liệu có phân phối lệch. Trong các trường hợp này, bạn sẽ cần phải sử dụng các kỹ thuật chuyển đổi dữ liệu phù hợp.
Độ nhọn (kurtosis) có thể được sử dụng để ước tính số lượng các giá trị ngoại lệ trong dữ liệu. Giá trị kurtosis bằng 0 có nghĩa là phân phối là phân phối chuẩn với không nhiều giá trị ngoại lệ. Giá trị kurtosis cao cho thấy rằng có thể có nhiều giá trị ngoại lệ trong dữ liệu và kurtosis thấp có nghĩa là ít ngoại lệ hơn trong dữ liệu.

Nguồn: https://community.sw.siemens.com/s/article/kurtosis
Cả độ nghiêng (skewness) và độ nhọn (kurtosis) đều hữu ích để hiểu rõ hơn về sự phân bố của dữ liệu, từ đó đưa ra phương án xử lý nếu phát hiện thấy tập dữ liệu không có phân phối gần như phân phối chuẩn. Chẳng hạn nếu như nếu dữ liệu bị lệch nhiều và/ hoặc có một số lượng lớn các giá trị ngoại lệ thì có thể sử dụng phép biến đổi phù hợp như lấy logarit để xử lý dữ liệu trước khi tiến hành phân tích.
Độ biến động của dữ liệu
Độ biến động của dữ liệu trong thống kê (variability) được sử dụng để đo lường sự phân bố của dữ liệu xung quanh giá trị trung bình. Các phương pháp khác nhau có thể được sử dụng để đo độ biến động của dữ liệu là giá trị phân vị (percentile), độ lệch chuẩn (standard deviation) và phương sai (variance).
Chẳng hạn một công ty thương mại điện tử đang thực hiện một số thay đổi về thiết kế để cải thiện thời gian mỗi khách hàng cần sử dụng để thực hiện một giao dịch. Trước khi thay đổi thiết kế, thời gian hoàn thành một giao dịch trung bình là 10 phút với độ lệch chuẩn 2 phút. Sau khi thay đổi thiết kế, thời gian cần thiết để hoàn thành giao dịch trung bình là 9 phút với độ lệch chuẩn 3 phút. Từ đây có thể đánh giá sự thay đối thiết kế đã có tác dụng làm giảm thời gian hoàn thành giao dịch, nhưng mức độ tác dụng cụ thể lên mỗi khách hàng là khác nhau.
Ngoài ra, việc tính toán độ biến động của dữ liệu cũng sẽ là cơ sở để các thuật toán dựa trên khoảng cách như K-Means hoặc KNN.